The Kalman filter, also known as linear quadratic estimation (LQE), is an algorithm that uses a series of measurements observed over time, containing noise (random variations) and other inaccuracies, and produces estimates of unknown variables that tend to be more precise than those based on a single measurement alone. More formally, the Kalman filter operates recursively on streams of noisy input data to produce a statistically optimal estimate of the underlying system state. The filter is named for Rudolf (Rudy) E. Kálmán, one of the primary developers of its theory.
The Kalman filter has numerous applications in technology. A common application is for guidance, navigation and controlof vehicles, particularly aircraft and spacecraft. Furthermore, the Kalman filter is a widely applied concept in time seriesanalysis used in fields such as signal processing and econometrics.
The algorithm works in a two-step process. In the prediction step, the Kalman filter produces estimates of the current state variables, along with their uncertainties. Once the outcome of the next measurement (necessarily corrupted with some amount of error, including random noise) is observed, these estimates are updated using a weighted average, with more weight being given to estimates with higher certainty. Because of the algorithm's recursive nature, it can run in real time using only the present input measurements and the previously calculated state; no additional past information is required.
From a theoretical standpoint, the main assumption of the Kalman filter is that the underlying system is a linear dynamical system and that all error terms and measurements have a Gaussian distribution (often a multivariate Gaussian distribution).
Extensions and generalizations to the method have also been developed, such as the extended Kalman filter and the unscented Kalman filter which work on nonlinear systems. The underlying model is a Bayesian model similar to a hidden Markov model but where the state space of the latent variables is continuous and where all latent and observed variables have Gaussian distributions.

 denotes the estimate of the system's state at time step k before the k-th measurement yk has been taken into account;
denotes the estimate of the system's state at time step k before the k-th measurement yk has been taken into account;  is the corresponding uncertainty.
is the corresponding uncertainty.Naming and historical development
The filter is named after Hungarian émigré Rudolf E. Kálmán, although Thorvald Nicolai Thiele[1][2] and Peter Swerling developed a similar algorithm earlier. Richard S. Bucy of the University of Southern California contributed to the theory, leading to it often being called the Kalman-Bucy filter. Stanley F. Schmidt is generally credited with developing the first implementation of a Kalman filter. It was during a visit by Kalman to the NASA Ames Research Center that he saw the applicability of his ideas to the problem of trajectory estimation for the Apollo program, leading to its incorporation in the Apollo navigation computer. This Kalman filter was first described and partially developed in technical papers by Swerling (1958), Kalman (1960) and Kalman and Bucy (1961).
Kalman filters have been vital in the implementation of the navigation systems of U.S. Navy nuclear ballistic missile submarines, and in the guidance and navigation systems of cruise missiles such as the U.S. Navy's Tomahawk missile and the U.S. Air Force's Air Launched Cruise Missile. It is also used in the guidance and navigation systems of the NASA Space Shuttle and theattitude control and navigation systems of the International Space Station.
This digital filter is sometimes called the Stratonovich–Kalman–Bucy filter because it is a special case of a more general, non-linear filter developed somewhat earlier by the Soviet mathematicianRuslan L. Stratonovich.[3][4][5][6] In fact, some of the special case linear filter's equations appeared in these papers by Stratonovich that were published before summer 1960, when Kalman met with Stratonovich during a conference in Moscow.
Overview of the calculation
The Kalman filter uses a system's dynamics model (e.g., physical laws of motion), known control inputs to that system, and multiple sequential measurements (such as from sensors) to form an estimate of the system's varying quantities (its state) that is better than the estimate obtained by using any one measurement alone. As such, it is a common sensor fusion and data fusionalgorithm.
All measurements and calculations based on models are estimates to some degree. Noisy sensor data, approximations in the equations that describe how a system changes, and external factors that are not accounted for introduce some uncertainty about the inferred values for a system's state. The Kalman filter averages a prediction of a system's state with a new measurement using a weighted average. The purpose of the weights is that values with better (i.e., smaller) estimated uncertainty are "trusted" more. The weights are calculated from the covariance, a measure of the estimated uncertainty of the prediction of the system's state. The result of the weighted average is a new state estimate that lies between the predicted and measured state, and has a better estimated uncertainty than either alone. This process is repeated every time step, with the new estimate and its covariance informing the prediction used in the following iteration. This means that the Kalman filter works recursively and requires only the last "best guess", rather than the entire history, of a system's state to calculate a new state.
Because the certainty of the measurements is often difficult to measure precisely, it is common to discuss the filter's behavior in terms of gain. The Kalman gain is a function of the relative certainty of the measurements and current state estimate, and can be "tuned" to achieve particular performance. With a high gain, the filter places more weight on the measurements, and thus follows them more closely. With a low gain, the filter follows the model predictions more closely, smoothing out noise but decreasing the responsiveness. At the extremes, a gain of one causes the filter to ignore the state estimate entirely, while a gain of zero causes the measurements to be ignored.
When performing the actual calculations for the filter (as discussed below), the state estimate and covariances are coded into matrices to handle the multiple dimensions involved in a single set of calculations. This allows for representation of linear relationships between different state variables (such as position, velocity, and acceleration) in any of the transition models or covariances.
Example application
As an example application, consider the problem of determining the precise location of a truck. The truck can be equipped with a GPS unit that provides an estimate of the position within a few meters. The GPS estimate is likely to be noisy; readings 'jump around' rapidly, though always remaining within a few meters of the real position. In addition, since the truck is expected to follow the laws of physics, its position can also be estimated by integrating its velocity over time, determined by keeping track of wheel revolutions and the angle of the steering wheel. This is a technique known as dead reckoning. Typically, dead reckoning will provide a very smooth estimate of the truck's position, but it will drift over time as small errors accumulate.
In this example, the Kalman filter can be thought of as operating in two distinct phases: predict and update. In the prediction phase, the truck's old position will be modified according to the physical laws of motion (the dynamic or "state transition" model) plus any changes produced by the accelerator pedal and steering wheel. Not only will a new position estimate be calculated, but a new covariance will be calculated as well. Perhaps the covariance is proportional to the speed of the truck because we are more uncertain about the accuracy of the dead reckoning estimate at high speeds but very certain about the position when moving slowly. Next, in the update phase, a measurement of the truck's position is taken from the GPS unit. Along with this measurement comes some amount of uncertainty, and its covariance relative to that of the prediction from the previous phase determines how much the new measurement will affect the updated prediction. Ideally, if the dead reckoning estimates tend to drift away from the real position, the GPS measurement should pull the position estimate back towards the real position but not disturb it to the point of becoming rapidly changing and noisy.
Technical description and context
The Kalman filter is an efficient recursive filter that estimates the internal state of a linear dynamic system from a series of noisy measurements. It is used in a wide range of engineering andeconometric applications from radar and computer vision to estimation of structural macroeconomic models,[7][8] and is an important topic in control theory and control systems engineering. Together with the linear-quadratic regulator (LQR), the Kalman filter solves the linear-quadratic-Gaussian control problem (LQG). The Kalman filter, the linear-quadratic regulator and the linear-quadratic-Gaussian controller are solutions to what arguably are the most fundamental problems in control theory.
In most applications, the internal state is much larger (more degrees of freedom) than the few "observable" parameters which are measured. However, by combining a series of measurements, the Kalman filter can estimate the entire internal state.
In Dempster-Shafer theory, each state equation or observation is considered a special case of a linear belief function and the Kalman filter is a special case of combining linear belief functions on a join-tree or Markov tree.
A wide variety of Kalman filters have now been developed, from Kalman's original formulation, now called the "simple" Kalman filter, the Kalman-Bucy filter, Schmidt's "extended" filter, theinformation filter, and a variety of "square-root" filters that were developed by Bierman, Thornton and many others. Perhaps the most commonly used type of very simple Kalman filter is the phase-locked loop, which is now ubiquitous in radios, especially frequency modulation (FM) radios, television sets, satellite communications receivers, outer space communications systems, and nearly any other electronic communications equipment.
Underlying dynamic system model
The Kalman filters are based on linear dynamic systems discretized in the time domain. They are modelled on a Markov chain built on linear operators perturbed by Gaussian noise. The state of the system is represented as a vector of real numbers. At each discrete time increment, a linear operator is applied to the state to generate the new state, with some noise mixed in, and optionally some information from the controls on the system if they are known. Then, another linear operator mixed with more noise generates the observed outputs from the true ("hidden") state. The Kalman filter may be regarded as analogous to the hidden Markov model, with the key difference that the hidden state variables take values in a continuous space (as opposed to a discrete state space as in the hidden Markov model). Additionally, the hidden Markov model can represent an arbitrary distribution for the next value of the state variables, in contrast to the Gaussian noise model that is used for the Kalman filter. There is a strong duality between the equations of the Kalman Filter and those of the hidden Markov model. A review of this and other models is given in Roweis and Ghahramani (1999)[9] and Hamilton (1994), Chapter 13.[10]
In order to use the Kalman filter to estimate the internal state of a process given only a sequence of noisy observations, one must model the process in accordance with the framework of the Kalman filter. This means specifying the following matrices: Fk, the state-transition model; Hk, the observation model; Qk, the covariance of the process noise; Rk, the covariance of the observation noise; and sometimes Bk, the control-input model, for each time-step, k, as described below.
The Kalman filter model assumes the true state at time k is evolved from the state at (k−1) according to

where
- Fk is the state transition model which is applied to the previous state xk−1;
- Bk is the control-input model which is applied to the control vector uk;
- wk is the process noise which is assumed to be drawn from a zero meanmultivariate normal distribution with covariance Qk.
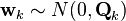
At time k an observation (or measurement) zk of the true state xk is made according to
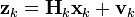
where Hk is the observation model which maps the true state space into the observed space and vk is the observation noise which is assumed to be zero mean Gaussian white noise with covariance Rk.

The initial state, and the noise vectors at each step {x0, w1, ..., wk, v1 ... vk} are all assumed to be mutually independent.
Many real dynamical systems do not exactly fit this model. In fact, unmodelled dynamics can seriously degrade the filter performance, even when it was supposed to work with unknown stochastic signals as inputs. The reason for this is that the effect of unmodelled dynamics depends on the input, and, therefore, can bring the estimation algorithm to instability (it diverges). On the other hand, independent white noise signals will not make the algorithm diverge. The problem of separating between measurement noise and unmodelled dynamics is a difficult one and is treated in control theory under the framework of robust control.

Details
The Kalman filter is a recursive estimator. This means that only the estimated state from the previous time step and the current measurement are needed to compute the estimate for the current state. In contrast to batch estimation techniques, no history of observations and/or estimates is required. In what follows, the notation 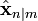 represents the estimate of
represents the estimate of  at time n given observations up to, and including at time m.
at time n given observations up to, and including at time m.
represents the estimate of at time n given observations up to, and including at time m.
The state of the filter is represented by two variables:
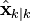 , the a posteriori state estimate at time k given observations up to and including at time k;
, the a posteriori state estimate at time k given observations up to and including at time k;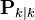 , the a posteriori error covariance matrix (a measure of the estimated accuracy of the state estimate).
, the a posteriori error covariance matrix (a measure of the estimated accuracy of the state estimate).
The Kalman filter can be written as a single equation, however it is most often conceptualized as two distinct phases: "Predict" and "Update". The predict phase uses the state estimate from the previous timestep to produce an estimate of the state at the current timestep. This predicted state estimate is also known as the a priori state estimate because, although it is an estimate of the state at the current timestep, it does not include observation information from the current timestep. In the update phase, the current a priori prediction is combined with current observation information to refine the state estimate. This improved estimate is termed the a posteriori state estimate.
Typically, the two phases alternate, with the prediction advancing the state until the next scheduled observation, and the update incorporating the observation. However, this is not necessary; if an observation is unavailable for some reason, the update may be skipped and multiple prediction steps performed. Likewise, if multiple independent observations are available at the same time, multiple update steps may be performed (typically with different observation matrices Hk).
Predict
| Predicted (a priori) state estimate | 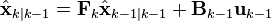 |
Predicted (a priori) estimate covariance
| 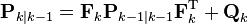 |
Update
| Innovation or measurement residual |  |
| Innovation (or residual) covariance |  |
| Optimal Kalman gain |  |
| Updated (a posteriori) state estimate |  |
| Updated (a posteriori) estimate covariance |  |
The formula for the updated estimate and covariance above is only valid for the optimal Kalman gain. Usage of other gain values require a more complex formula found in the derivations section.
Invariants
If the model is accurate, and the values for  and
and  accurately reflect the distribution of the initial state values, then the following invariants are preserved: (all estimates have a mean error of zero)
accurately reflect the distribution of the initial state values, then the following invariants are preserved: (all estimates have a mean error of zero)
and accurately reflect the distribution of the initial state values, then the following invariants are preserved: (all estimates have a mean error of zero)![\textrm{E}[\textbf{x}_k - \hat{\textbf{x}}_{k|k}] = \textrm{E}[\textbf{x}_k - \hat{\textbf{x}}_{k|k-1}] = 0](http://upload.wikimedia.org/math/4/c/4/4c4bbb2da083dae032f5a7930e7b5d80.png)
![\textrm{E}[\tilde{\textbf{y}}_k] = 0](http://upload.wikimedia.org/math/0/0/7/00703cccab98e464367ae2b34e9b1493.png)
where ![\textrm{E}[\xi]](http://upload.wikimedia.org/math/6/2/2/622bdf3feac7f49bbef4950f48b8fd45.png) is the expected value of
is the expected value of 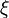 , and covariance matrices accurately reflect the covariance of estimates
, and covariance matrices accurately reflect the covariance of estimates
is the expected value of , and covariance matrices accurately reflect the covariance of estimates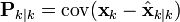
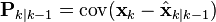
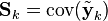
Estimation of the noise covariances Qk and Rk
Practical implementation of the Kalman Filter is often difficult due to the inability in getting a good estimate of the noise covariance matrices Qk and Rk. Extensive research has been done in this field to estimate these covariances from data. One of the more promising approaches to do this is the Autocovariance Least-Squares (ALS) technique that uses autocovariances of routine operating data to estimate the covariances.[11][12] The GNU Octave code used to calculate the noise covariance matrices using the ALS technique is available online under the GNU General Public License license.[13]
Optimality and performance
It is known from the theory that the Kalman filter is optimal in case that a) the model perfectly matches the real system, b) the entering noise is white and c) the covariances of the noise are exactly known. Several methods for the noise covariance estimation have been proposed during past decades. One, ALS, was mentioned in the previous paragraph. After the covariances are identified, it is useful to evaluate the performance of the filter, i.e. whether it is possible to improve the state estimation quality. It is well known that, if the Kalman filter works optimally, the innovation sequence (the output prediction error) is a white noise. The whiteness property reflects the state estimation quality. For evaluation of the filter performance it is necessary to inspect the whiteness property of the innovations. Several different methods can be used for this purpose. Three optimality tests with numerical examples are described in [14]
Example application, technical
Consider a truck on perfectly frictionless, infinitely long straight rails. Initially the truck is stationary at position 0, but it is buffeted this way and that by random acceleration. We measure the position of the truck every Δt seconds, but these measurements are imprecise; we want to maintain a model of where the truck is and what its velocity is. We show here how we derive the model from which we create our Kalman filter.
Since F, H, R and Q are constant, their time indices are dropped.
The position and velocity of the truck are described by the linear state space

where  is the velocity, that is, the derivative of position with respect to time.
is the velocity, that is, the derivative of position with respect to time.
is the velocity, that is, the derivative of position with respect to time.
We assume that between the (k−1) and k timestep the truck undergoes a constant acceleration of ak that is normally distributed, with mean 0 and standard deviation σa. From Newton's laws of motion we conclude that

(note that there is no  term since we have no known control inputs) where
term since we have no known control inputs) where
term since we have no known control inputs) where
and

so that

where  and
and
and
At each time step, a noisy measurement of the true position of the truck is made. Let us suppose the measurement noise vk is also normally distributed, with mean 0 and standard deviation σz.
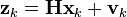
where

and
![\textbf{R} = \textrm{E}[\textbf{v}_k \textbf{v}_k^{\text{T}}] = \begin{bmatrix} \sigma_z^2 \end{bmatrix}](http://upload.wikimedia.org/math/1/3/c/13c0f6c1c05e1576664884f7b32ba0e2.png)
We know the initial starting state of the truck with perfect precision, so we initialize

and to tell the filter that we know the exact position, we give it a zero covariance matrix:
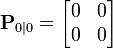
If the initial position and velocity are not known perfectly the covariance matrix should be initialized with a suitably large number, say L, on its diagonal.

The filter will then prefer the information from the first measurements over the information already in the model.
Derivations
Deriving the a posteriori estimate covariance matrix
Starting with our invariant on the error covariance Pk|k as above
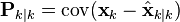
substitute in the definition of

and substitute 

and 

and by collecting the error vectors we get
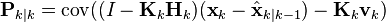
Since the measurement error vk is uncorrelated with the other terms, this becomes
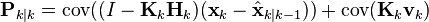
by the properties of vector covariance this becomes

which, using our invariant on Pk|k-1 and the definition of Rk becomes

This formula (sometimes known as the "Joseph form" of the covariance update equation) is valid for any value of Kk. It turns out that if Kk is the optimal Kalman gain, this can be simplified further as shown below.
Kalman gain derivation
The Kalman filter is a minimum mean-square error estimator. The error in the a posteriori state estimation is

We seek to minimize the expected value of the square of the magnitude of this vector, ![\textrm{E}[\|\textbf{x}_{k} - \hat{\textbf{x}}_{k|k}\|^2]](http://upload.wikimedia.org/math/5/2/2/522e3e14b94039fb4b13c7fa4c567d2e.png) . This is equivalent to minimizing the trace of the a posteriori estimate covariance matrix . By expanding out the terms in the equation above and collecting, we get:
. This is equivalent to minimizing the trace of the a posteriori estimate covariance matrix . By expanding out the terms in the equation above and collecting, we get:
. This is equivalent to minimizing the trace of the a posteriori estimate covariance matrix . By expanding out the terms in the equation above and collecting, we get:

The trace is minimized when its matrix derivative with respect to the gain matrix is zero. Using the gradient matrix rules and the symmetry of the matrices involved we find that

Solving this for Kk yields the Kalman gain:


This gain, which is known as the optimal Kalman gain, is the one that yields MMSE estimates when used.
Simplification of the a posteriori error covariance formula
The formula used to calculate the a posteriori error covariance can be simplified when the Kalman gain equals the optimal value derived above. Multiplying both sides of our Kalman gain formula on the right by SkKkT, it follows that
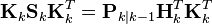
Referring back to our expanded formula for the a posteriori error covariance,

we find the last two terms cancel out, giving

This formula is computationally cheaper and thus nearly always used in practice, but is only correct for the optimal gain. If arithmetic precision is unusually low causing problems with numerical stability, or if a non-optimal Kalman gain is deliberately used, this simplification cannot be applied; the a posteriori error covariance formula as derived above must be used.
Sensitivity analysis
The Kalman filtering equations provide an estimate of the state and its error covariance recursively. The estimate and its quality depend on the system parameters and the noise statistics fed as inputs to the estimator. This section analyzes the effect of uncertainties in the statistical inputs to the filter.[15] In the absence of reliable statistics or the true values of noise covariance matrices  and
and  , the expression
, the expression
and its error covariance recursively. The estimate and its quality depend on the system parameters and the noise statistics fed as inputs to the estimator. This section analyzes the effect of uncertainties in the statistical inputs to the filter.[15] In the absence of reliable statistics or the true values of noise covariance matrices and , the expression
no longer provides the actual error covariance. In other words, ![\textbf{P}_{k|k} \neq E[(\textbf{x}_k - \hat{\textbf{x}}_{k|k})(\textbf{x}_k - \hat{\textbf{x}}_{k|k})^T]](http://upload.wikimedia.org/math/6/d/c/6dcddf96d2239895d1eedbe449b64696.png) . In most real time applications the covariance matrices that are used in designing the Kalman filter are different from the actual noise covariances matrices.[citation needed] This sensitivity analysis describes the behavior of the estimation error covariance when the noise covariances as well as the system matrices
. In most real time applications the covariance matrices that are used in designing the Kalman filter are different from the actual noise covariances matrices.[citation needed] This sensitivity analysis describes the behavior of the estimation error covariance when the noise covariances as well as the system matrices  and
and  that are fed as inputs to the filter are incorrect. Thus, the sensitivity analysis describes the robustness (or sensitivity) of the estimator to misspecified statistical and parametric inputs to the estimator.
that are fed as inputs to the filter are incorrect. Thus, the sensitivity analysis describes the robustness (or sensitivity) of the estimator to misspecified statistical and parametric inputs to the estimator.
. In most real time applications the covariance matrices that are used in designing the Kalman filter are different from the actual noise covariances matrices.[citation needed] This sensitivity analysis describes the behavior of the estimation error covariance when the noise covariances as well as the system matrices and that are fed as inputs to the filter are incorrect. Thus, the sensitivity analysis describes the robustness (or sensitivity) of the estimator to misspecified statistical and parametric inputs to the estimator.
This discussion is limited to the error sensitivity analysis for the case of statistical uncertainties. Here the actual noise covariances are denoted by  and
and 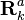 respectively, whereas the design values used in the estimator are
respectively, whereas the design values used in the estimator are  and
and 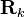 respectively. The actual error covariance is denoted by
respectively. The actual error covariance is denoted by  and as computed by the Kalman filter is referred to as the Riccati variable. When
and as computed by the Kalman filter is referred to as the Riccati variable. When  and
and  , this means that
, this means that  . While computing the actual error covariance using
. While computing the actual error covariance using ![\textbf{P}_{k|k}^a = E[(\textbf{x}_k - \hat{\textbf{x}}_{k|k})(\textbf{x}_k - \hat{\textbf{x}}_{k|k})^T]](http://upload.wikimedia.org/math/0/8/1/08122116063817c73d7c518cd5ab11c2.png) , substituting for
, substituting for  and using the fact that
and using the fact that ![E[\textbf{w}_k\textbf{w}_k^T] = \textbf{Q}_{k}^a](http://upload.wikimedia.org/math/2/b/1/2b16e05254bd5a19dff06ef5c0336f35.png) and
and ![E[\textbf{v}_k\textbf{v}_k^T] = \textbf{R}_{k}^a](http://upload.wikimedia.org/math/4/2/9/429f355a01eb641c8b800675564531e7.png) , results in the following recursive equations for :
, results in the following recursive equations for :
and respectively, whereas the design values used in the estimator are and respectively. The actual error covariance is denoted by and as computed by the Kalman filter is referred to as the Riccati variable. When and , this means that . While computing the actual error covariance using , substituting for and using the fact that and , results in the following recursive equations for :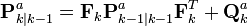
and

While computing , by design the filter implicitly assumes that ![E[\textbf{w}_k\textbf{w}_k^T] = \textbf{Q}_{k}](http://upload.wikimedia.org/math/3/6/e/36ed54c00e00654104db80d4b51a6a5c.png) and
and ![E[\textbf{v}_k\textbf{v}_k^T] = \textbf{R}_{k}](http://upload.wikimedia.org/math/5/5/0/550cc1e2b0cd8d29e1cbea2d591d2a58.png) . Note that the recursive expressions for and are identical except for the presence of
. Note that the recursive expressions for and are identical except for the presence of  and
and  in place of the design values and respectively.
in place of the design values and respectively.
, by design the filter implicitly assumes that and . Note that the recursive expressions for and are identical except for the presence of and in place of the design values and respectively.Square root form
One problem with the Kalman filter is its numerical stability. If the process noise covariance Qk is small, round-off error often causes a small positive eigenvalue to be computed as a negative number. This renders the numerical representation of the state covariance matrix P indefinite, while its true form is positive-definite.
Positive definite matrices have the property that they have a triangular matrix square root P = S·ST. This can be computed efficiently using the Cholesky factorization algorithm, but more importantly, if the covariance is kept in this form, it can never have a negative diagonal or become asymmetric. An equivalent form, which avoids many of the square root operations required by the matrix square root yet preserves the desirable numerical properties, is the U-D decomposition form, P = U·D·UT, where U is a unit triangular matrix (with unit diagonal), and D is a diagonal matrix.
Between the two, the U-D factorization uses the same amount of storage, and somewhat less computation, and is the most commonly used square root form. (Early literature on the relative efficiency is somewhat misleading, as it assumed that square roots were much more time-consuming than divisions,[16]:69 while on 21-st century computers they are only slightly more expensive.)
Efficient algorithms for the Kalman prediction and update steps in the square root form were developed by G. J. Bierman and C. L. Thornton.[16][17]
The L·D·LT decomposition of the innovation covariance matrix Sk is the basis for another type of numerically efficient and robust square root filter.[18] The algorithm starts with the LU decomposition as implemented in the Linear Algebra PACKage (LAPACK). These results are further factored into the L·D·LT structure with methods given by Golub and Van Loan (algorithm 4.1.2) for a symmetric nonsingular matrix.[19] Any singular covariance matrix is pivoted so that the first diagonal partition is nonsingular and well-conditioned. The pivoting algorithm must retain any portion of the innovation covariance matrix directly corresponding to observed state-variables Hk·xk|k-1 that are associated with auxiliary observations in yk. The L·D·LT square-root filter requiresorthogonalization of the observation vector.[17][18] This may be done with the inverse square-root of the covariance matrix for the auxiliary variables using Method 2 in Higham (2002, p. 263).[20]
Relationship to recursive Bayesian estimation
The Kalman filter can be considered to be one of the most simple dynamic Bayesian networks. The Kalman filter calculates estimates of the true values of states recursively over time using incoming measurements and a mathematical process model. Similarly, recursive Bayesian estimation calculates estimates of an unknown probability density function (PDF) recursively over time using incoming measurements and a mathematical process model.[21]
In recursive Bayesian estimation, the true state is assumed to be an unobserved Markov process, and the measurements are the observed states of a hidden Markov model (HMM).

Because of the Markov assumption, the true state is conditionally independent of all earlier states given the immediately previous state.
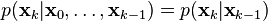
Similarly the measurement at the k-th timestep is dependent only upon the current state and is conditionally independent of all other states given the current state.

Using these assumptions the probability distribution over all states of the hidden Markov model can be written simply as:
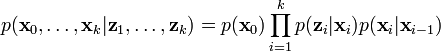
However, when the Kalman filter is used to estimate the state x, the probability distribution of interest is that associated with the current states conditioned on the measurements up to the current timestep. This is achieved by marginalizing out the previous states and dividing by the probability of the measurement set.
This leads to the predict and update steps of the Kalman filter written probabilistically. The probability distribution associated with the predicted state is the sum (integral) of the products of the probability distribution associated with the transition from the (k - 1)-th timestep to the k-th and the probability distribution associated with the previous state, over all possible  .
.
.
The measurement set up to time t is
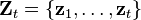
The probability distribution of the update is proportional to the product of the measurement likelihood and the predicted state.

The denominator

is a normalization term.
The remaining probability density functions are



Note that the PDF at the previous timestep is inductively assumed to be the estimated state and covariance. This is justified because, as an optimal estimator, the Kalman filter makes best use of the measurements, therefore the PDF for 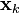 given the measurements
given the measurements 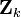 is the Kalman filter estimate.
is the Kalman filter estimate.
given the measurements is the Kalman filter estimate.Information filter
In the information filter, or inverse covariance filter, the estimated covariance and estimated state are replaced by the information matrix and information vector respectively. These are defined as:
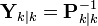

Similarly the predicted covariance and state have equivalent information forms, defined as:


as have the measurement covariance and measurement vector, which are defined as:
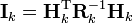

The information update now becomes a trivial sum.


The main advantage of the information filter is that N measurements can be filtered at each timestep simply by summing their information matrices and vectors.


To predict the information filter the information matrix and vector can be converted back to their state space equivalents, or alternatively the information space prediction can be used.
![\textbf{M}_{k} =
[\textbf{F}_{k}^{-1}]^{\text{T}} \textbf{Y}_{k-1|k-1} \textbf{F}_{k}^{-1}](http://upload.wikimedia.org/math/2/6/2/26208bc8cd8a6061d4e26c0165797af5.png)
![\textbf{C}_{k} =
\textbf{M}_{k} [\textbf{M}_{k}+\textbf{Q}_{k}^{-1}]^{-1}](http://upload.wikimedia.org/math/b/a/b/baba972b698cfcfce00c6fdb6c3c52e9.png)

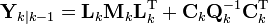
![\hat{\textbf{y}}_{k|k-1} =
\textbf{L}_{k} [\textbf{F}_{k}^{-1}]^{\text{T}}\hat{\textbf{y}}_{k-1|k-1}](http://upload.wikimedia.org/math/a/d/a/adaa6e7d41ff680f915be3e0d4d2e4ca.png)
Note that if F and Q are time invariant these values can be cached. Note also that F and Q need to be invertible.
Fixed-lag smoother
The optimal fixed-lag smoother provides the optimal estimate of  for a given fixed-lag
for a given fixed-lag  using the measurements from
using the measurements from  to . It can be derived using the previous theory via an augmented state, and the main equation of the filter is the following:
to . It can be derived using the previous theory via an augmented state, and the main equation of the filter is the following:
for a given fixed-lag using the measurements from to . It can be derived using the previous theory via an augmented state, and the main equation of the filter is the following:
where:
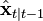 is estimated via a standard Kalman filter;
is estimated via a standard Kalman filter; is the innovation produced considering the estimate of the standard Kalman filter;
is the innovation produced considering the estimate of the standard Kalman filter;- the various
 with
with  are new variables, i.e. they do not appear in the standard Kalman filter;
are new variables, i.e. they do not appear in the standard Kalman filter; - the gains are computed via the following scheme:
-
- and
- where
 and
and 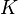 are the prediction error covariance and the gains of the standard Kalman filter (i.e.,
are the prediction error covariance and the gains of the standard Kalman filter (i.e.,  ).
).
![K^{(i)} =
P^{(i)} H^{T}
\left[
H P H^{T} + R
\right]^{-1}](http://upload.wikimedia.org/math/8/4/c/84c9732d7cc69960772a191e4d09eaed.png)
![P^{(i)} =
P
\left[
\left[
F - K H
\right]^{T}
\right]^{i}](http://upload.wikimedia.org/math/2/4/d/24d65d3a8c4f87b6d2902be6ae846da9.png)
If the estimation error covariance is defined so that
![P_{i} :=
E
\left[
\left(
\textbf{x}_{t-i} - \hat{\textbf{x}}_{t-i|t}
\right)^{*}
\left(
\textbf{x}_{t-i} - \hat{\textbf{x}}_{t-i|t}
\right)
|
z_{1} \ldots z_{t}
\right],](http://upload.wikimedia.org/math/7/c/e/7ce57204cfdfb46f02b3b52ffaa5a79e.png)
then we have that the improvement on the estimation of  is given by:
is given by:
is given by:![P-P_{i} =
\sum_{j = 0}^{i}
\left[
P^{(j)} H^{T}
\left[
H P H^{T} + R
\right]^{-1}
H \left( P^{(i)} \right)^{T}
\right]](http://upload.wikimedia.org/math/1/6/0/1607f4f21976ef2cac996926f36aad95.png)
Fixed-interval smoothers
The optimal fixed-interval smoother provides the optimal estimate of  (
( ) using the measurements from a fixed interval to
) using the measurements from a fixed interval to  . This is also called "Kalman Smoothing". There are several smoothing algorithms in common use.
. This is also called "Kalman Smoothing". There are several smoothing algorithms in common use.
() using the measurements from a fixed interval to . This is also called "Kalman Smoothing". There are several smoothing algorithms in common use.Rauch–Tung–Striebel
The Rauch–Tung–Striebel (RTS) smoother is an efficient two-pass algorithm for fixed interval smoothing.[22]
The forward pass is the same as the regular Kalman filter algorithm. These filtered state estimates and covariances are saved for use in the backwards pass.
and covariances are saved for use in the backwards pass.
In the backwards pass, we compute the smoothed state estimates  and covariances
and covariances  . We start at the last time step and proceed backwards in time using the following recursive equations:
. We start at the last time step and proceed backwards in time using the following recursive equations:
and covariances . We start at the last time step and proceed backwards in time using the following recursive equations:

where

Modified Bryson–Frazier smoother
An alternative to the RTS algorithm is the modified Bryson–Frazier (MBF) fixed interval smoother developed by Bierman.[17] This also uses a backward pass that processes data saved from the Kalman filter forward pass. The equations for the backward pass involve the recursive computation of data which are used at each observation time to compute the smoothed state and covariance.The recursive equations arewhere is the residual covariance and
is the residual covariance and  . The smoothed state and covariance can then be found by substitution in the equationsorAn important advantage of the MBF is that it does not require finding the inverse of the covariance matrix.
. The smoothed state and covariance can then be found by substitution in the equationsorAn important advantage of the MBF is that it does not require finding the inverse of the covariance matrix.Minimum-variance smoother
The minimum-variance smoother can attain the best-possible error performance, provided that the models are linear, their parameters and the noise statistics are known precisely.[23] This smoother is a time-varying state-space generalization of the optimal non-causal Wiener filter.The smoother calculations are done in two passes. The forward calculations involve a one-step-ahead predictor and are given byThe above system is known as the inverse Wiener-Hopf factor. The backward recursion is the adjoint of the above forward system. The result of the backward pass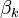 may be calculated by operating the forward equations on the time-reversed
may be calculated by operating the forward equations on the time-reversed  and time reversing the result. In the case of output estimation, the smoothed estimate is given byTaking the causal part of this minimum-variance smoother yieldswhich is identical to the minimum-variance Kalman filter. The above solutions minimize the variance of the output estimation error. Note that the Rauch-Tung-Striebel smoother derivation assumes that the underlying distributions are Gaussian, whereas the minimum-variance solutions do not. Optimal smoothers for state estimation and input estimation can be constructed similarly. A continuous-time version of the above smoother is described in.[24][25]Expectation-maximization algorithms may be employed to calculate approximate maximum likelihood-estimates of unknown state-space parameters within minimum-variance filters and smoothers. Often uncertainties remain within problem assumptions. A smoother that accommodates uncertainties can be designed by adding a positive definite term to the Riccati equation.[26]In cases where the models are nonlinear, step-wise linearizations may be within the minimum-variance filter and smoother recursions (Extended Kalman filtering).
and time reversing the result. In the case of output estimation, the smoothed estimate is given byTaking the causal part of this minimum-variance smoother yieldswhich is identical to the minimum-variance Kalman filter. The above solutions minimize the variance of the output estimation error. Note that the Rauch-Tung-Striebel smoother derivation assumes that the underlying distributions are Gaussian, whereas the minimum-variance solutions do not. Optimal smoothers for state estimation and input estimation can be constructed similarly. A continuous-time version of the above smoother is described in.[24][25]Expectation-maximization algorithms may be employed to calculate approximate maximum likelihood-estimates of unknown state-space parameters within minimum-variance filters and smoothers. Often uncertainties remain within problem assumptions. A smoother that accommodates uncertainties can be designed by adding a positive definite term to the Riccati equation.[26]In cases where the models are nonlinear, step-wise linearizations may be within the minimum-variance filter and smoother recursions (Extended Kalman filtering).Non-linear filters
The basic Kalman filter is limited to a linear assumption. More complex systems, however, can be nonlinear. The non-linearity can be associated either with the process model or with the observation model or with both.
Extended Kalman filter
Main article: Extended Kalman filter
In the extended Kalman filter (EKF), the state transition and observation models need not be linear functions of the state but may instead be non-linear functions. These functions are ofdifferentiable type.The function f can be used to compute the predicted state from the previous estimate and similarly the function h can be used to compute the predicted measurement from the predicted state. However, f and h cannot be applied to the covariance directly. Instead a matrix of partial derivatives (the Jacobian) is computed.At each timestep the Jacobian is evaluated with current predicted states. These matrices can be used in the Kalman filter equations. This process essentially linearizes the non-linear function around the current estimate.Unscented Kalman filter
When the state transition and observation models—that is, the predict and update functions and
and 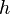 —are highly non-linear, the extended Kalman filter can give particularly poor performance.[27]This is because the covariance is propagated through linearization of the underlying non-linear model. The unscented Kalman filter (UKF) [27] uses a deterministic sampling technique known as the unscented transform to pick a minimal set of sample points (called sigma points) around the mean. These sigma points are then propagated through the non-linear functions, from which the mean and covariance of the estimate are then recovered. The result is a filter which more accurately captures the true mean and covariance. (This can be verified using Monte Carlo sampling or through a Taylor series expansion of the posterior statistics.) In addition, this technique removes the requirement to explicitly calculate Jacobians, which for complex functions can be a difficult task in itself (i.e., requiring complicated derivatives if done analytically or being computationally costly if done numerically).
—are highly non-linear, the extended Kalman filter can give particularly poor performance.[27]This is because the covariance is propagated through linearization of the underlying non-linear model. The unscented Kalman filter (UKF) [27] uses a deterministic sampling technique known as the unscented transform to pick a minimal set of sample points (called sigma points) around the mean. These sigma points are then propagated through the non-linear functions, from which the mean and covariance of the estimate are then recovered. The result is a filter which more accurately captures the true mean and covariance. (This can be verified using Monte Carlo sampling or through a Taylor series expansion of the posterior statistics.) In addition, this technique removes the requirement to explicitly calculate Jacobians, which for complex functions can be a difficult task in itself (i.e., requiring complicated derivatives if done analytically or being computationally costly if done numerically).- Predict
As with the EKF, the UKF prediction can be used independently from the UKF update, in combination with a linear (or indeed EKF) update, or vice versa.The estimated state and covariance are augmented with the mean and covariance of the process noise.A set of 2L+1 sigma points is derived from the augmented state and covariance where L is the dimension of the augmented state.whereis the ith column of the matrix square root ofusing the definition: square root A of matrix B satisfies .
.
The matrix square root should be calculated using numerically efficient and stable methods such as the Cholesky decomposition.The sigma points are propagated through the transition function f.where . The weighted sigma points are recombined to produce the predicted state and covariance.where the weights for the state and covariance are given by:
. The weighted sigma points are recombined to produce the predicted state and covariance.where the weights for the state and covariance are given by: and
and 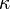 control the spread of the sigma points.
control the spread of the sigma points.  is related to the distribution of
is related to the distribution of  . Normal values are
. Normal values are  ,
,  and
and  . If the true distribution of is Gaussian, is optimal.[28]
. If the true distribution of is Gaussian, is optimal.[28]- Update
The predicted state and covariance are augmented as before, except now with the mean and covariance of the measurement noise.As before, a set of 2L + 1 sigma points is derived from the augmented state and covariance where L is the dimension of the augmented state.Alternatively if the UKF prediction has been used the sigma points themselves can be augmented along the following lineswhereThe sigma points are projected through the observation function h.The weighted sigma points are recombined to produce the predicted measurement and predicted measurement covariance.The state-measurement cross-covariance matrix,is used to compute the UKF Kalman gain.As with the Kalman filter, the updated state is the predicted state plus the innovation weighted by the Kalman gain,And the updated covariance is the predicted covariance, minus the predicted measurement covariance, weighted by the Kalman gain.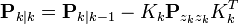
Kalman–Bucy filter
The Kalman–Bucy filter (named after Richard Snowden Bucy) is a continuous time version of the Kalman filter.[29][30]It is based on the state space modelwhere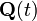 and
and  represent the intensities of the two white noise terms
represent the intensities of the two white noise terms 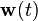 and
and  , respectively.The filter consists of two differential equations, one for the state estimate and one for the covariance:where the Kalman gain is given byNote that in this expression for
, respectively.The filter consists of two differential equations, one for the state estimate and one for the covariance:where the Kalman gain is given byNote that in this expression for the covariance of the observation noise represents at the same time the covariance of the prediction error (or innovation)
the covariance of the observation noise represents at the same time the covariance of the prediction error (or innovation)  ; these covariances are equal only in the case of continuous time.[31]The distinction between the prediction and update steps of discrete-time Kalman filtering does not exist in continuous time.The second differential equation, for the covariance, is an example of a Riccati equation.
; these covariances are equal only in the case of continuous time.[31]The distinction between the prediction and update steps of discrete-time Kalman filtering does not exist in continuous time.The second differential equation, for the covariance, is an example of a Riccati equation.Hybrid Kalman filter
Most physical systems are represented as continuous-time models while discrete-time measurements are frequently taken for state estimation via a digital processor. Therefore, the system model and measurement model are given bywhere .
.
- Initialize
![\hat{\mathbf{x}}_{0|0}=E\bigl[\mathbf{x}(t_0)\bigr], \mathbf{P}_{0|0}=Var\bigl[\mathbf{x}(t_0)\bigr]](http://upload.wikimedia.org/math/4/e/9/4e983f7e29c7acaad69a74ce7b2654e4.png)
- Predict
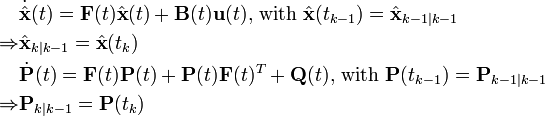
The prediction equations are derived from those of continuous-time Kalman filter without update from measurements, i.e.,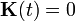 . The predicted state and covariance are calculated respectively by solving a set of differential equations with the initial value equal to the estimate at the previous step.
. The predicted state and covariance are calculated respectively by solving a set of differential equations with the initial value equal to the estimate at the previous step.- Update



The update equations are identical to those of the discrete-time Kalman filter.Variants for the recovery of sparse signals
Recently the traditional Kalman filter has been employed for the recovery of sparse, possibly dynamic, signals from noisy observations. Both works [32] and [33] utilize notions from the theory ofcompressed sensing/sampling, such as the restricted isometry property and related probabilistic recovery arguments, for sequentially estimating the sparse state in intrinsically low-dimensional systems.
Applications
- Attitude and Heading Reference Systems
- Autopilot
- Battery state of charge (SoC) estimation [1][2]
- Brain-computer interface
- Chaotic signals
- Tracking and Vertex Fitting of charged particles in Particle Detectors [34]
- Tracking of objects in computer vision
- Dynamic positioning
- Economics, in particular macroeconomics, time series, and econometrics
- Inertial guidance system
- Orbit Determination
- Radar tracker
- Satellite navigation systems
- Seismology [3]
- Sensorless control of AC motor variable-frequency drives
- Simultaneous localization and mapping
- Speech enhancement
- Weather forecasting
- Navigation system
- 3D modeling
- Structural health monitoring
- Human sensorimotor processing[35]
以上來源 英文維基















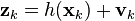
![\textbf{x}_{k-1|k-1}^{a} = [ \hat{\textbf{x}}_{k-1|k-1}^{T} \quad E[\textbf{w}_{k}^{T}] \ ]^{T}](http://upload.wikimedia.org/math/7/c/0/7c0c53eef72ef92fff5265ffd5a5f68d.png)
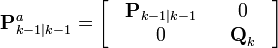







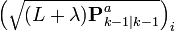


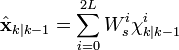
![\textbf{P}_{k|k-1} = \sum_{i=0}^{2L} W_{c}^{i}\ [\chi_{k|k-1}^{i} - \hat{\textbf{x}}_{k|k-1}] [\chi_{k|k-1}^{i} - \hat{\textbf{x}}_{k|k-1}]^{T}](http://upload.wikimedia.org/math/5/1/a/51a88054b452591833406b0018a83781.png)



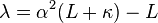
![\textbf{x}_{k|k-1}^{a} = [ \hat{\textbf{x}}_{k|k-1}^{T} \quad E[\textbf{v}_{k}^{T}] \ ]^{T}](http://upload.wikimedia.org/math/f/a/6/fa6d80e1bb88f3fe9739339130520c8d.png)
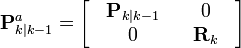




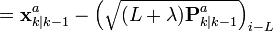
![\chi_{k|k-1} := [ \chi_{k|k-1}^T \quad E[\textbf{v}_{k}^{T}] \ ]^{T} \pm \sqrt{ (L + \lambda) \textbf{R}_{k}^{a} }](http://upload.wikimedia.org/math/9/6/9/9696ba46d924b5cca5cc17de316051a4.png)

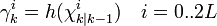

![\textbf{P}_{z_{k}z_{k}} = \sum_{i=0}^{2L} W_{c}^{i}\ [\gamma_{k}^{i} - \hat{\textbf{z}}_{k}] [\gamma_{k}^{i} - \hat{\textbf{z}}_{k}]^{T}](http://upload.wikimedia.org/math/6/d/3/6d3da795ea81bc12de85506725726b27.png)
![\textbf{P}_{x_{k}z_{k}} = \sum_{i=0}^{2L} W_{c}^{i}\ [\chi_{k|k-1}^{i} - \hat{\textbf{x}}_{k|k-1}] [\gamma_{k}^{i} - \hat{\textbf{z}}_{k}]^{T}](http://upload.wikimedia.org/math/2/c/9/2c9c83f91f94b10ce37f1f62190784ac.png)






應用實例
卡爾曼濾波的一個典型實例是從一組有限的,包含噪聲的,對物體位置的觀察序列(可能有偏差)預測出物體的位置的坐標及速度。在很多工程應用(如雷達、計算機視覺)中都可以找到它的身影。同時,卡爾曼濾波也是控制理論以及控制系統工程中的一個重要課題。
例如,對於雷達來說,人們感興趣的是其能夠跟蹤目標。但目標的位置、速度、加速度的測量值往往在任何時候都有噪聲。卡爾曼濾波利用目標的動態信息,設法去掉噪聲的影響,得到一個關於目標位置的好的估計。這個估計可以是對當前目標位置的估計(濾波),也可以是對於將來位置的估計(預測),也可以是對過去位置的估計(插值或平滑)。
命名
這種濾波方法以它的發明者魯道夫.E.卡爾曼(Rudolph E. Kalman)命名,但是根據文獻可知實際上Peter Swerling在更早之前就提出了一種類似的演算法。
斯坦利.施密特(Stanley Schmidt)首次實現了卡爾曼濾波器。卡爾曼在NASA埃姆斯研究中心訪問時,發現他的方法對於解決阿波羅計劃的軌道預測很有用,後來阿波羅飛船的導航電腦便使用了這種濾波器。 關於這種濾波器的論文由Swerling (1958)、Kalman (1960)與 Kalman and Bucy (1961)發表。
目前,卡爾曼濾波已經有很多不同的實現.卡爾曼最初提出的形式現在一般稱為簡單卡爾曼濾波器。除此以外,還有施密特擴展濾波器、信息濾波器以及很多Bierman, Thornton 開發的平方根濾波器的變種。也許最常見的卡爾曼濾波器是鎖相環,它在收音機、計算機和幾乎任何視頻或通訊設備中廣泛存在。
基本動態系統模型
卡爾曼濾波建立在線性代數和隱馬爾可夫模型(hidden Markov model)上。其基本動態系統可以用一個馬爾可夫鏈表示,該馬爾可夫鏈建立在一個被高斯噪聲(即常態分佈的噪聲)干擾的線性算子上的。系統的狀態可以用一個元素為實數的向量表示。 隨著離散時間的每一個增加,這個線性算子就會作用在當前狀態上,產生一個新的狀態,並也會帶入一些噪聲,同時系統的一些已知的控制器的控制信息也會被加入。同時,另一個受噪聲干擾的線性算子產生出這些隱含狀態的可見輸出。
為了從一系列有噪聲的觀察數據中用卡爾曼濾波器估計出被觀察過程的內部狀態,我們必須把這個過程在卡爾曼濾波的框架下建立模型。也就是說對於每一步k,定義矩陣Fk, Hk, Qk, Rk,有時也需要定義Bk,如下。
卡爾曼濾波模型假設k時刻的真實狀態是從(k − 1)時刻的狀態演化而來,符合下式:
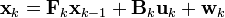
其中
時刻k,對真實狀態 xk的一個測量zk滿足下式:
其中Hk是觀測模型,它把真實狀態空間映射成觀測空間,vk 是觀測噪聲,其均值為零,協方差矩陣為Rk,且服從常態分佈。
初始狀態以及每一時刻的噪聲{x0, w1, ..., wk, v1 ... vk} 都認為是互相獨立的.
實際上,很多真實世界的動態系統都並不確切的符合這個模型;但是由於卡爾曼濾波器被設計在有噪聲的情況下工作,一個近似的符合已經可以使這個濾波器非常有用了。更多其它更複雜的卡爾曼濾波器的變種,在下邊討論中有描述。

卡爾曼濾波器
卡爾曼濾波是一種遞歸的估計,即只要獲知上一時刻狀態的估計值以及當前狀態的觀測值就可以計算出當前狀態的估計值,因此不需要記錄觀測或者估計的歷史信息。卡爾曼濾波器與大多數濾波器不同之處,在於它是一種純粹的時域濾波器,它不需要像低通濾波器等頻域濾波器那樣,需要在頻域設計再轉換到時域實現。
卡爾曼濾波器的狀態由以下兩個變數表示:
- ,在時刻k 的狀態的估計;
- ,誤差相關矩陣,度量估計值的精確程度。
卡爾曼濾波器的操作包括兩個階段:預測與更新。在預測階段,濾波器使用上一狀態的估計,做出對當前狀態的估計。在更新階段,濾波器利用對當前狀態的觀測值優化在預測階段獲得的預測值,以獲得一個更精確的新估計值。
預測
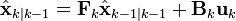 (預測狀態)
(預測狀態) (預測估計協方差矩陣)
(預測估計協方差矩陣)
更新
首先要算出以下三個量:
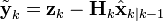 (測量餘量,measurement residual)
(測量餘量,measurement residual) (測量餘量協方差)
(測量餘量協方差)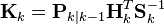 (最優卡爾曼增益)
(最優卡爾曼增益)
然後用它們來更新濾波器變數x 與P :
 (更新的狀態估計)
(更新的狀態估計)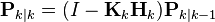 (更新的協方差估計)
(更新的協方差估計)
使用上述公式計算僅在最優卡爾曼增益的時候有效。使用其他增益的話,公式要複雜一些,請參見推導。
僅在最優卡爾曼增益的時候有效。使用其他增益的話,公式要複雜一些,請參見推導。不變數(Invariant)
如果模型準確,而且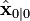 與 的值準確的反映了最初狀態的分布,那麼以下不變數就保持不變:所有估計的誤差均值為零
與 的值準確的反映了最初狀態的分布,那麼以下不變數就保持不變:所有估計的誤差均值為零
與 的值準確的反映了最初狀態的分布,那麼以下不變數就保持不變:所有估計的誤差均值為零
且 協方差矩陣 準確的反映了估計的協方差:
請注意,其中![\textrm{E}[\textbf{a}]](http://upload.wikimedia.org/math/c/d/3/cd34547a1cd577a331c13c681b2d1bf8.png) 表示
表示 的期望值,
的期望值, ![\textrm{cov}(\textbf{a}) = \textrm{E}[\textbf{a}\textbf{a}^T]](http://upload.wikimedia.org/math/d/2/7/d27f414efcd30770cfb2e541b1a61972.png) 。
。
表示的期望值, 。實例
考慮在無摩擦的、無限長的直軌道上的一輛車。該車最初停在位置 0 處,但時不時受到隨機的衝擊。我們每隔Δt秒即測量車的位置,但是這個測量是非精確的;我們想建立一個關於其位置以及速度的模型。我們來看如何推導出這個模型以及如何從這個模型得到卡爾曼濾波器。
因為車上無動力,所以我們可以忽略掉Bk 和uk。由於F、H、R 和Q 是常數,所以時間下標可以去掉。
車的位置以及速度(或者更加一般的,一個粒子的運動狀態)可以被線性狀態空間描述如下:
其中 是速度,也就是位置對於時間的導數。
是速度,也就是位置對於時間的導數。
是速度,也就是位置對於時間的導數。
其中
且
我們可以發現
![\textbf{Q} = \textrm{cov}(\textbf{G}a) = \textrm{E}[(\textbf{G}a)(\textbf{G}a)^{T}] = \textbf{G} \textrm{E}[a^2] \textbf{G}^{T} = \textbf{G}[\sigma_a^2]\textbf{G}^{T} = \sigma_a^2 \textbf{G}\textbf{G}^{T}](http://upload.wikimedia.org/math/0/e/c/0ec2936f75d8424cbc2de843a269cec8.png) (因為 σa 是一個純量).
(因為 σa 是一個純量).
在每一時刻,我們對其位置進行測量,測量受到噪聲干擾.我們假設噪聲服從常態分佈,均值為0,標準差為σz。

其中
且
![\textbf{R} = \textrm{E}[\textbf{v}_k \textbf{v}_k^{T}] = \begin{bmatrix} \sigma_z^2 \end{bmatrix}](http://upload.wikimedia.org/math/9/1/a/91af04d30a1712b8237b2d4fc82e50a9.png)
如果我們知道足夠精確的車最初的位置,那麼我們可以初始化
並且,我們告訴濾波器我們知道確切的初始位置,我們給出一個協方差矩陣:

如果我們不確切的知道最初的位置與速度,那麼協方差矩陣可以初始化為一個對角線元素是B的矩陣,B取一個合適的比較大的數。
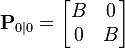
此時,與使用模型中已有信息相比,濾波器更傾向於使用初次測量值的信息。
推導
推導後驗協方差矩陣
按照上邊的定義,我們從誤差協方差開始推導如下:
開始推導如下: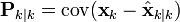
代入
再代入 
與
整理誤差向量,得

因為測量誤差vk 與其他項是非相關的,因此有
利用協方差矩陣的性質,此式可以寫作
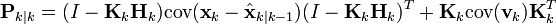
使用不變數Pk|k-1以及Rk的定義 這一項可以寫作 : 這一公式對於任何卡爾曼增益Kk都成立。如果Kk是最優卡爾曼增益,則可以進一步簡化,請見下文。
這一公式對於任何卡爾曼增益Kk都成立。如果Kk是最優卡爾曼增益,則可以進一步簡化,請見下文。
這一公式對於任何卡爾曼增益Kk都成立。如果Kk是最優卡爾曼增益,則可以進一步簡化,請見下文。最優卡爾曼增益的推導
卡爾曼濾波器是一個最小均方誤差估計器,後驗狀態誤差估計(英文:a posteriori state estimate)是

我們最小化這個矢量幅度平方的期望值,![\textrm{E}[|\textbf{x}_{k} - \hat{\textbf{x}}_{k|k}|^2]](http://upload.wikimedia.org/math/3/b/4/3b40022edea8b7435f22199f63727849.png) ,這等同於最小化後驗估計協方差矩陣 Pk|k的跡(trace)。將上面方程中的項展開、抵消,得到:
,這等同於最小化後驗估計協方差矩陣 Pk|k的跡(trace)。將上面方程中的項展開、抵消,得到:
,這等同於最小化後驗估計協方差矩陣 Pk|k的跡(trace)。將上面方程中的項展開、抵消,得到:
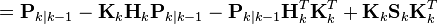

此處須用到一個常用的式子, 如下:
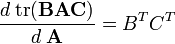
從這個方程解出卡爾曼增益Kk:


這個增益稱為最優卡爾曼增益,在使用時得到最小均方誤差。
後驗誤差協方差公式的化簡
在卡爾曼增益等於上面導出的最優值時,計算後驗協方差的公式可以進行簡化。在卡爾曼增益公式兩側的右邊都乘以 SkKkT 得到
根據上面後驗誤差協方差展開公式,
最後兩項可以抵消,得到
 .
.
這個公式的計算比較簡單,所以實際中總是使用這個公式,但是需注意這公式僅在使用最優卡爾曼增益的時候它才成立。如果算術精度總是很低而導致數值穩定性出現問題,或者特意使用非最優卡爾曼增益,那麼就不能使用這個簡化;必須使用上面導出的後驗誤差協方差公式。
與遞歸Bayesian估計之間的關係
假設真正的狀態是無法觀察的馬爾可夫過程,測量結果是從隱性馬爾可夫模型觀察到的狀態。
根據馬爾可夫假設,真正的狀態僅受最近一個狀態影響而與其它以前狀態無關。
與此類似,在時刻 k 測量只與當前狀態有關而與其它狀態無關。
根據這些假設,隱性馬爾可夫模型所有狀態的機率分布可以簡化為:

然而,當卡爾曼濾波器用來估計狀態x的時候,我們感興趣的機率分布,是基於目前為止所有個測量值來得到的當前狀態之機率分布
信息濾波器
非線性濾波器
基本卡爾曼濾波器(The basic Kalman filter)是限制在線性的假設之下。然而,大部份非平凡的(non-trial)的系統都是非線性系統。其中的「非線性性質」(non-linearity )可能是伴隨存在過程模型(process model)中或觀測模型(observation model)中,或者兩者兼有之。
擴展卡爾曼濾波器[編輯]
在擴展卡爾曼濾波器(Extended Kalman Filter,簡稱EKF)中狀態轉換和觀測模型不需要是狀態的線性函數,可替換為(可微的)函數。


函數 f 可以用來從過去的估計值中計算預測的狀態,相似的,函數 h可以用來以預測的狀態計算預測的測量值。然而 f 和 h 不能直接的應用在協方差中,取而代之的是計算偏導矩陣(Jacobian)。
在每一步中使用當前的估計狀態計算Jacobian矩陣,這幾個矩陣可以用在卡爾曼濾波器的方程中。這個過程,實質上將非線性的函數在當前估計值處線性化了。
這樣一來,卡爾曼濾波器的等式為:
預測

使用Jacobians矩陣更新模型


更新

預測
如同擴展卡爾曼濾波器(EKF)一樣, UKF的預測過程可以獨立於UKF的更新過程之外,與一個線性的(或者確實是擴展卡爾曼濾波器的)更新過程合併來使用;或者,UKF的預測過程與更新過程在上述中地位互換亦可。
應用
- An Introduction to the Kalman Filter, SIGGRAPH 2001 Course, Greg Welch and Gary Bishop
- Kalman filtering chapter from Stochastic Models, Estimation, by Peter Maybeck
- Kalman Filter webpage, with lots of links
- Kalman Filtering
- The unscented Kalman filter for nonlinear estimation
- Kalman Filters, thorough introduction to several types, together with applications to Robot Localization
參考文獻
- Gelb A., editor. Applied optimal estimation. MIT Press, 1974.
- Kalman, R. E. A New Approach to Linear Filtering and Prediction Problems, Transactions of the ASME - Journal of Basic Engineering Vol. 82: pp. 35-45 (1960)
- Kalman, R. E., Bucy R. S., New Results in Linear Filtering and Prediction Theory, Transactions of the ASME - Journal of Basic Engineering Vol. 83: pp. 95-107 (1961)
- [JU97] Julier, Simon J. and Jeffery K. Uhlmann. A New Extension of the Kalman Filter to nonlinear Systems. In The Proceedings of AeroSense: The 11th International Symposium on Aerospace/Defense Sensing,Simulation and Controls, Multi Sensor Fusion, Tracking and Resource Management II, SPIE, 1997.
- Harvey, A.C. Forecasting, Structural Time Series Models and the Kalman Filter. Cambridge University Press, Cambridge, 1989.
以上來自中文維基
Kalman Filter 介紹
1. 什麼是卡爾曼濾波器(What is the Kalman Filter?)
在學習卡爾曼濾波器之前,首先看看為什麼叫“卡爾曼”。跟其他著名的理論(例如傅立葉變換,泰勒級數等等)一樣,卡爾曼也是一個人的名字,而跟他們不同的是,他是個現代人!
卡爾曼全名Rudolf Emil Kalman,匈牙利數學家,1930年出生於匈牙利首都布達佩斯。1953,1954年于麻省理工學院分別獲得電機工程學士及碩士學位。1957年于哥倫比亞大學獲得博士學位。我們現在要學習的卡爾曼濾波器,正是源于他的博士論文和1960年發表的論文《A New Approach to Linear Filtering and Prediction Problems》(線性濾波與預測問題的新方法)。如果對這編論文有興趣,可以到這裏的位址下載: http://www.cs.unc.edu/~welch/kalman/media/pdf/Kalman1960.pdf 。 簡單來說,卡爾曼濾波器是一個“optimal recursive data processing algorithm(最優化自回歸資料處理演算法)”。對於解決很大部分的問題,他是最優,效率最高甚至是最有用的。他的廣泛應用已經超過30年,包括機器人導航,控制,感測器資料融合甚至在軍事方面的雷達系統以及導彈追蹤等等。近年來更被應用於電腦圖像處理,例如頭臉識別,圖像分割,圖像邊緣檢測等等。
2.卡爾曼濾波器的介紹(Introduction to the Kalman Filter)
為了可以更加容易的理解卡爾曼濾波器,這裏會應用形象的描述方法來講解,而不是像大多數參考書那樣羅列一大堆的數學公式和數學符號。但是,他的5條公式是其核心內容。結合現代的電腦,其實卡爾曼的程式相當的簡單,只要你理解了他的那5條公式。
在介紹他的5條公式之前,先讓我們來根據下面的例子一步一步的探索。
假設我們要研究的物件是一個房間的溫度。根據你的經驗判斷,這個房間的溫度是恒定的,也就是下一分鐘的溫度等於現在這一分鐘的溫度(假設我們用一分鐘來做時間單位)。假設你對你的經驗不是100%的相信,可能會有上下偏差幾度。我們把這些偏差看成是高斯白雜訊(White Gaussian Noise),也就是這些偏差跟前後時間是沒有關係的而且符合高斯分配(Gaussian Distribution)。另外,我們在房間裏放一個溫度計,但是這個溫度計也不準確的,測量值會比實際值偏差。我們也把這些偏差看成是高斯白雜訊。
好了,現在對於某一分鐘我們有兩個有關於該房間的溫度值:你根據經驗的預測值(系統的預測值)和溫度計的值(測量值)。下面我們要用這兩個值結合他們各自的雜訊來估算出房間的實際溫度值。
假如我們要估算k時刻的是實際溫度值。首先你要根據k-1時刻的溫度值,來預測k時刻的溫度。因為你相信溫度是恒定的,所以你會得到k時刻的溫度預測值是跟k-1時刻一樣的,假設是23度,同時該值的高斯雜訊的偏差是5度(5是這樣得到的:如果k-1時刻估算出的最優溫度值的偏差是3,你對自己預測的不確定度是4度,他們平方相加再開方,就是5)。然後,你從溫度計那裏得到了k時刻的溫度值,假設是25度,同時該值的偏差是4度。
由於我們用於估算k時刻的實際溫度有兩個溫度值,分別是23度和25度。究竟實際溫度是多少呢?相信自己還是相信溫度計呢?究竟相信誰多一點,我們可以用他們的covariance來判斷。因為Kg^2=5^2/(5^2+4^2),所以Kg=0.78,我們可以估算出k時刻的實際溫度值是:23+0.78*(25-23)=24.56度。可以看出,因為溫度計的covariance比較小(比較相信溫度計),所以估算出的最優溫度值偏向溫度計的值。
現在我們已經得到k時刻的最優溫度值了,下一步就是要進入k+1時刻,進行新的最優估算。到現在為止,好像還沒看到什麼自回歸的東西出現。對了,在進入k+1時刻之前,我們還要算出k時刻那個最優值(24.56度)的偏差。演算法如下:((1-Kg)*5^2)^0.5=2.35。這裏的5就是上面的k時刻你預測的那個23度溫度值的偏差,得出的2.35就是進入k+1時刻以後k時刻估算出的最優溫度值的偏差(對應於上面的3)。
就是這樣,卡爾曼濾波器就不斷的把covariance遞迴,從而估算出最優的溫度值。他運行的很快,而且它只保留了上一時刻的covariance。上面的Kg,就是卡爾曼增益(Kalman Gain)。他可以隨不同的時刻而改變他自己的值,是不是很神奇!
下面就要言歸正傳,討論真正工程系統上的卡爾曼。
3. 卡爾曼濾波器演算法(The Kalman Filter Algorithm)
在這一部分,我們就來描述源於Dr Kalman 的卡爾曼濾波器。下面的描述,會涉及一些基本的概念知識,包括概率(Probability),隨即變數(Random Variable),高斯或正態分配(Gaussian Distribution)還有State-space Model等等。但對於卡爾曼濾波器的詳細證明,這裏不能一一描述。
首先,我們先要引入一個離散控制過程的系統。該系統可用一個線性隨機微分方程(Linear Stochastic Difference equation)來描述:
X(k)=A X(k-1)+B U(k)+W(k)
再加上系統的測量值:
Z(k)=H X(k)+V(k)
上兩式子中,X(k)是k時刻的系統狀態,U(k)是k時刻對系統的控制量。A和B是系統參數,對於多模型系統,他們為矩陣。Z(k)是k時刻的測量值,H是測量系統的參數,對於多測量系統,H為矩陣。W(k)和V(k)分別表示過程和測量的雜訊。他們被假設成高斯白雜訊(White Gaussian Noise),他們的covariance 分別是Q,R(這裏我們假設他們不隨系統狀態變化而變化)。
對於滿足上面的條件(線性隨機微分系統,過程和測量都是高斯白雜訊),卡爾曼濾波器是最優的資訊處理器。下面我們來用他們結合他們的covariances 來估算系統的最優化輸出(類似上一節那個溫度的例子)。
首先我們要利用系統的過程模型,來預測下一狀態的系統。假設現在的系統狀態是k,根據系統的模型,可以基於系統的上一狀態而預測出現在狀態:
X(k|k-1)=A X(k-1|k-1)+B U(k) ……….. (1)
式(1)中,X(k|k-1)是利用上一狀態預測的結果,X(k-1|k-1)是上一狀態最優的結果,U(k)為現在狀態的控制量,如果沒有控制量,它可以為0。
到現在為止,我們的系統結果已經更新了,可是,對應於X(k|k-1)的covariance還沒更新。我們用P表示covariance:
P(k|k-1)=A P(k-1|k-1) A’+Q ……… (2)
式(2)中,P(k|k-1)是X(k|k-1)對應的covariance,P(k-1|k-1)是X(k-1|k-1)對應的covariance,A’表示A的轉置矩陣,Q是系統過程的covariance。式子1,2就是卡爾曼濾波器5個公式當中的前兩個,也就是對系統的預測。
現在我們有了現在狀態的預測結果,然後我們再收集現在狀態的測量值。結合預測值和測量值,我們可以得到現在狀態(k)的最優化估算值X(k|k):
X(k|k)= X(k|k-1)+Kg(k) (Z(k)-H X(k|k-1)) ……… (3)
其中Kg為卡爾曼增益(Kalman Gain):
Kg(k)= P(k|k-1) H’ / (H P(k|k-1) H’ + R) ……… (4)
到現在為止,我們已經得到了k狀態下最優的估算值X(k|k)。但是為了要另卡爾曼濾波器不斷的運行下去直到系統過程結束,我們還要更新k狀態下X(k|k)的covariance:
P(k|k)=(I-Kg(k) H)P(k|k-1) ……… (5)
其中I 為1的矩陣,對於單模型單測量,I=1。當系統進入k+1狀態時,P(k|k)就是式子(2)的P(k-1|k-1)。這樣,演算法就可以自回歸的運算下去。
卡爾曼濾波器的原理基本描述了,式子1,2,3,4和5就是他的5 個基本公式。根據這5個公式,可以很容易的實現電腦的程式。
下面,我會用程式舉一個實際運行的例子。。。
4. 簡單例子(A Simple Example)
這裏我們結合第二第三節,舉一個非常簡單的例子來說明卡爾曼濾波器的工作過程。所舉的例子是進一步描述第二節的例子,而且還會配以程式類比結果。
根據第二節的描述,把房間看成一個系統,然後對這個系統建模。當然,我們見的模型不需要非常地精確。我們所知道的這個房間的溫度是跟前一時刻的溫度相同的,所以A=1。沒有控制量,所以U(k)=0。因此得出:
X(k|k-1)=X(k-1|k-1) ……….. (6)
式子(2)可以改成:
P(k|k-1)=P(k-1|k-1) +Q ……… (7)
因為測量的值是溫度計的,跟溫度直接對應,所以H=1。式子3,4,5可以改成以下:
X(k|k)= X(k|k-1)+Kg(k) (Z(k)-X(k|k-1)) ……… (8)
Kg(k)= P(k|k-1) / (P(k|k-1) + R) ……… (9)
P(k|k)=(1-Kg(k))P(k|k-1) ……… (10)
現在我們模擬一組測量值作為輸入。假設房間的真實溫度為25度,我模擬了200個測量值,這些測量值的平均值為25度,但是加入了標準偏差為幾度的高斯白雜訊(在圖中為藍線)。
為了令卡爾曼濾波器開始工作,我們需要告訴卡爾曼兩個零時刻的初始值,是X(0|0)和P(0|0)。他們的值不用太在意,隨便給一個就可以了,因為隨著卡爾曼的工作,X會逐漸的收斂。但是對於P,一般不要取0,因為這樣可能會令卡爾曼完全相信你給定的X(0|0)是系統最優的,從而使演算法不能收斂。我選了X(0|0)=1度,P(0|0)=10。
該系統的真實溫度為25度,圖中用黑線表示。圖中紅線是卡爾曼濾波器輸出的最優化結果(該結果在演算法中設置了Q=1e-6,R=1e-1)。

以上內容來自無名部落格MaMaSon's blog Kalman Filter 介紹
寫得很好,就順便留下紀錄了,原部落格留言處還有matlab程式碼不節錄
對岸的資料,也算詳細
內容超詳細,可惜還沒看
有很多額外的參考資料



{kind=link}
沒有留言:
張貼留言